
 How to resolve AdBlock issue?
How to resolve AdBlock issue? Dela Quist: Segmentation broke A/B testing but personalization will kill it!

The way we test today only works with batch and blast
In the last few years digital marketing has been transformed. Marketers have moved from sending the same message to everybody on the list – batch and blast, to segmentation, where messages are specific to particular customer segments or persona’s. According to the 2016 Econsultancy Email Industry Census the majority of respondents claim to be doing basic segmentation while around 1/3 claim to be doing advanced segmentation.
Today customers are savvier, harder to engage and more empowered than ever, so now the goal for many marketers is to make each message specific and relevant to the individual through personalization, making testing more important than it has ever been. Test Test Test has long been our mantra, but in the age of the customer this has become Test or Die.
However marketing faces a problem – there’s a huge elephant in the room. Live testing – the way we A/B test today is broken. It only works if you batch and blast at a mailing frequency of no more than 2 or 3 emails per week. That’s because live testing just doesn’t scale and there is nothing you or any marketing automation tool can do to fix that.
To help you understand why scale is important in testing I would like to share some data taken from Touchstone a virtual subject line (SL) test platform we developed to solve this very problem.
Performance Curve – No test
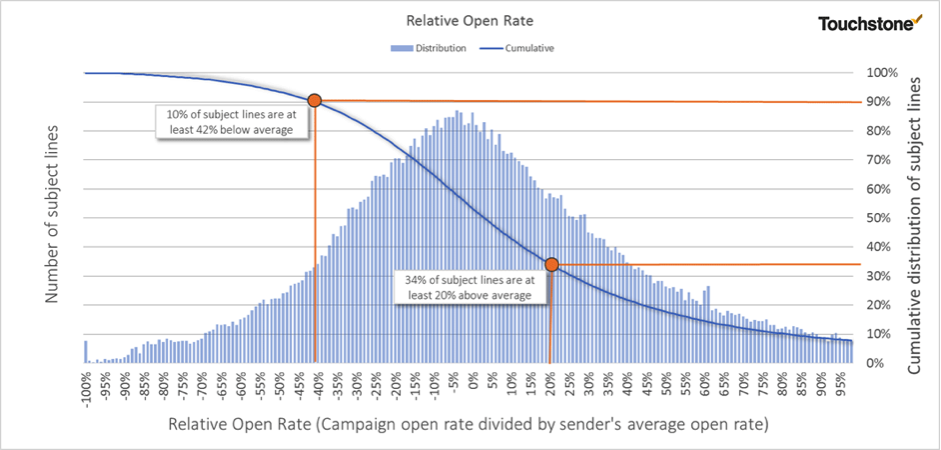
This chart teaches us a lot about selecting SL’s and performing SL tests. This amazing bell curve taken from the campaign data held with Touchstone shows the distribution of open rates for every SL in its database. All open rates are computed relative to the sender's average open rate, so an open rate of +20% here means that it performed 20% above average.
Let’s start with how many SL’s you should test to ensure you get a significant lift. The term A/B test would imply that two is ok, but the data would suggest otherwise. The data shows us that any given SL has roughly 1 chance out of 3 of performing at least 20% above average. In other words, to be sure to get a 20% lift in your open rate, you should test at least 3 SL’s on every single campaign.
We can also see what happens if you don't test, or test too little. If you use only one subject line, there is a 1/3 chance that it will underperform the average by at least 20% and a 1/10 chance that it will perform 42% below average. So if you select only two subject lines in your test, then each has a 1/3 chance of underperforming by >20%. In other words there is a 1/9 chance that both will be 20% or more below average. SL “A” is bad, “B” is worse – bad beats worse, but they are both crap!
The more SL’s you test the greater the chance that at least one of them will be one of those great SL’s to the right of this chart, and reduce the chances that you'll send one of the less effective SL’s on the left.
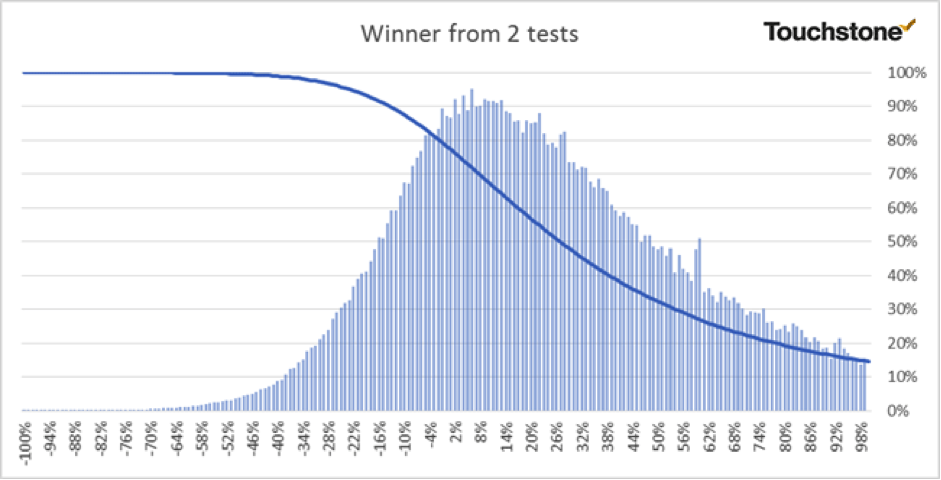
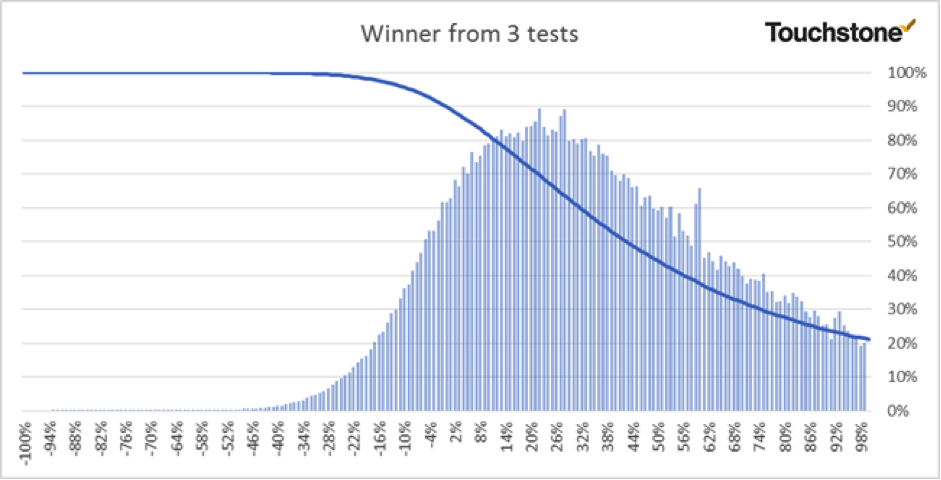
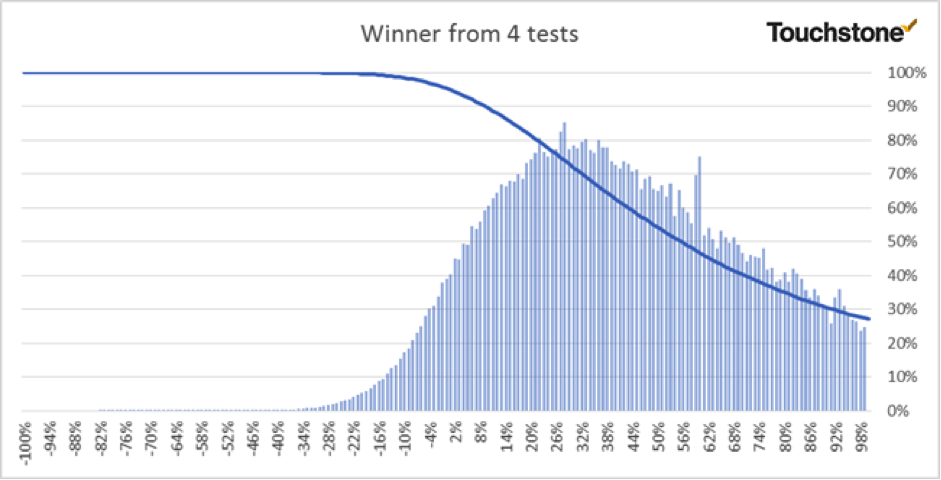
As you will see from the next 3 charts every incremental SL you test improves your chances of getting a lift.
Predicted Performance from 2 Subject Line test
Predicted Performance from 3 Subject Line test
Predicted Performance from 4 Subject Line test
The same is true whether you decide to optimize for Click Rate or CTO rate as this handy chart taken from the data demonstrates.
|
Predicted Gain |
|||
|
Variations |
Open % |
Click % |
CTO % |
|
2 |
3% |
0% |
0% |
|
3 |
21% |
42% |
25% |
|
4 |
33% |
79% |
47% |
|
5 |
44% |
111% |
65% |
|
6 |
53% |
141% |
80% |
|
7 |
60% |
169% |
94% |
|
8 |
68% |
194% |
106% |
|
9 |
74% |
220% |
117% |
|
10 |
81% |
242% |
128% |
So if you test 3 SL’s the chances are you can expect a 21% improvement in your open rate 42% in click rate and 25% improvement in your CTO. Looking at this more closely what’s really interesting is the fact that it’s actually easier you get more than twice the gain if you optimise for clicks rather than opens. Put another way you need to write and test fewer SL’s.
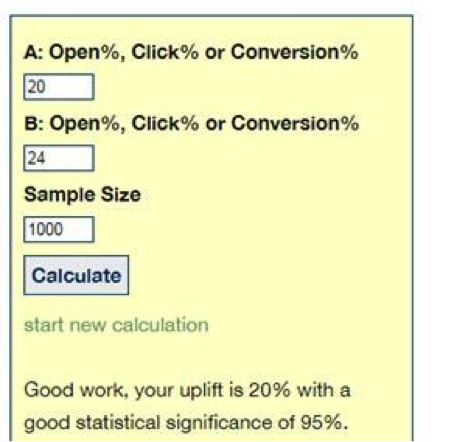
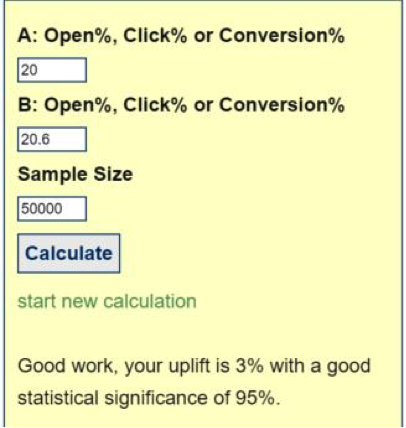
The second part of the challenge marketers’ face is selecting a big enough sample to deliver a statistically significant result. There are several free sample size calculators around and the one we are showing is provided by Influencer Tim Watson of Zettasphere.
Statistical significance relates two important pieces of information: the size of the lift generated by the winning variation, and the size of the segments used for testing. If the size of the lift is small, then you need a larger sample size to ‘see’ the effect, and vice versa.
A major problem which is too rarely stated is this: the size of the lift is not known until after the test has been run. Thus, when computing their sample sizes, marketers need to pick the lift size they would like to get, and generally pick a fairly large number, say a 25% lift. Why do they pick such a large number? Because (a) it reduces the required sample size for the test, and (b) they think they’ll actually achieve a better lift by using a larger number, i.e. that by aiming for a 25% lift, they’re more likely to actually get it.
However, this means that if neither of the two subject lines performs 25% better than the other, then the result will not be statistically significant. In other words, the test would be meaningless.
So what are the odds that neither of the two subject line would perform more than 25% better than the other?
It turns out that a 25% lift is very large. Indeed, when we look at the hundreds of brands who upload their email data onto Touchstone, we see that there is a less than 50% chance that one of the two subject lines generates a 25% lift.
In other words, when expecting a 25% lift to compute segment size, there is a less than 50% chance that he test will be statistically meaningful. An obvious solution to this problem is simply to use larger segments, so that even a small lift would be statistically significant. However, larger segments means that more subscribers see the losing subject line, which means lost revenue as well as potentially negative impacts on your brand perception.
How many ‘more’ subscribers are we talking about, here? To see a 20% lift, you need roughly 1000 people in your sample. To see a 3% lift, you need roughly five times more: 50,000. That is a lot of human guinea pigs.
Finally there is the question of time.
The longer the test runs the more accurate the result but as we do more segmentation and move toward personalization, the longer it takes to get the campaigns out the door. This has the effect of putting a tremendous amount of pressure on marketers to reduce the time a test runs as much as possible. But as the chart below shows from a test we ran on our own newsletter Email-Worx ,the SL that starts out in front is not always the SL that wins.
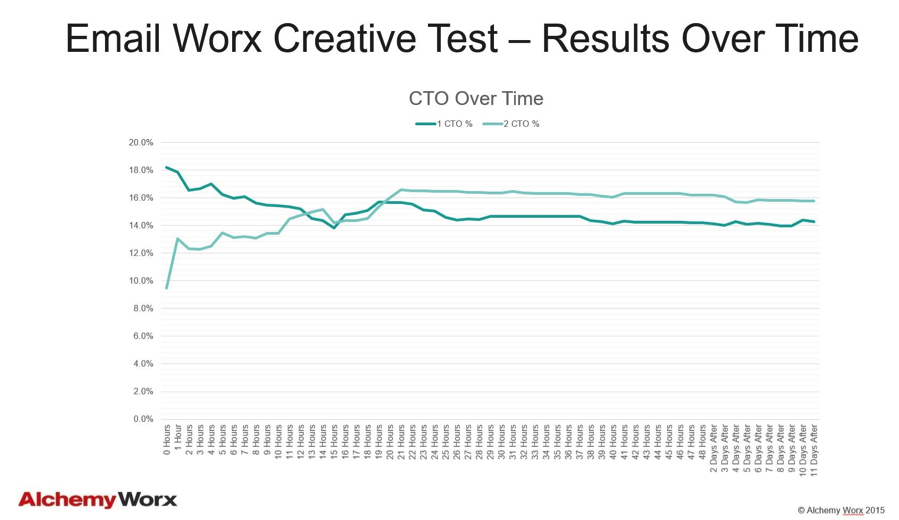
As you can see from the evidence provided, live testing subject lines is only really practical if you batch and blast at a low mailing frequency. In today’s world where there is an enormous amount of pressure on marketers to deliver a much better experience to their customers through personalization testing is needed more than ever before. Live A/B testing just does not scale for 3 reasons.
- Every test requires you to build, test, sign off and deploy an email and that takes up a lot of time no matter how good your ESP is.
- Every test burns up a portion, however small, of your subscribers and exposes them to losing/irrelevant messages – fine if you only A/B tests a couple of times a week, but not if you send highly personalized communications to hundreds of micro segments
- Every test takes or should take hours to run properly and if you have a typical production cycle there are not enough hours in the day.
The solution is to test VIRTUALLY either by using a tool like a virtual test platform like Touchstone or mine your campaign data in such a way as to achieve the same result. We do it by using a machine learning algorithm to create a virtual replica of the user’s customer base. So you actually test the SL’s on “virtual customers” and not real customers. If you want proof that it works, some Touchstone users test over 1000 SL’s/month the record is 669 in a week!
Don’t forget, in the age of the customer every live test that fails leaves money on the table and has long-term consequences.
About the author
 Dela Quist, is CMO of Alchemy Worx, the largest email marketing agency. He is a highly experienced expert email marketer with a strong background in digital media and advertising.
Dela Quist, is CMO of Alchemy Worx, the largest email marketing agency. He is a highly experienced expert email marketer with a strong background in digital media and advertising.
Services include: email marketing strategy, email marketing best practice, email campaign planning, email design, email copywriting, HTML email production, email campaign deployment, email delivery and reputation, spam filter avoidance, reporting, and analysis.