
 How to resolve AdBlock issue?
How to resolve AdBlock issue? The Power of Serendipity: How Randomness Enhances Personalization

We are all familiar with the experience. Pick your favorite online application: Netflix. Facebook. Amazon, or my personal go-to app - Spotify. They all use recommendation systems to enhance your personalized experience. Undoubtedly, you’ve been left staring at what feels like an endless loop of redundant content. Clicked that video about EPL soccer? Guess what you’re going to see next. Shopped for a Thanksgiving turkey costume? Guess what you’ll be seeing for the next several months in the “for you” section.
Recommendation systems create the experience that brings us the content that we’ve demonstrated interest in. We value this. We want it.
But there is (at least) one downside to this approach: by recommending what they know you prefer, these systems miss the chance to expose you to new and different information, which limits their ability to learn more about you.
How can this risk be mitigated? By leveraging the power of randomness.
Recommendation Systems
A “Recommendation System” is a data-driven algorithm that analyzes user preferences and behavior to suggest personalized content. We are surrounded by them in all facets of our life. Many of the emails we receive - newsletters, promotions, pretty much everything (but political blasts) - have been touched by personalization-driven recommendation systems:
- Which items are you likely to purchase based on your past browsing activity?
- What content have you demonstrated interest in by reading and engaging on websites?
How do these systems work? How do they present personalized recommendations across so many different use cases? How can Amazon provide recommendations of fashion trends, lawn care products, and electronics? What about recommending songs, videos or books?
The answer to these questions can be surprisingly simple and has been around for a very long time. The answer is “Cosine Similarity,” which consists of two pieces: Vectors and Cosines. Humor me while we return briefly to the days of algebra long ago (or skip ahead to avoid the math).
Algebra 101
- Vectors are a set of numbers that describe a line.
- Cosine is a measurement of the size of an angle (mathematically, this isn’t technically true, but at least it is a good proxy for a true definition).
Given two sets of numbers, a Cosine describes how close the Vectors representing those numbers are. Cosine values closer to 1 represent vectors close to each other, and numbers closer to -1 represent vectors further away from each other.
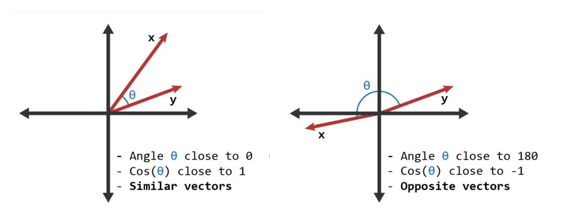
What does this have to do with recommendations? If I have a technique to represent two different “things” as a set of numbers, then I can compare those “things” by using a Cosine value.
Things as numbers? What does that mean, and how is it possible? These questions are beyond the scope of this article. But accept (at least for now) that such techniques are possible, and use tools called “Embeddings”. With these “Embedding” tools, a recommendation system can take any “thing” (a person, a song, a product) and convert it to a set of numbers. Then using algebra, the recommendation system can compute cosines and figure out which are close - and recommend the closest “thing” to the user.
Example
A recommendation system looks at my personal data and uses an “Embedding” tool to compute my set of numbers as (0, 0.8, 0.9). The same system then evaluates all of the ice creams at my local Baskin Robbins store and discovers that Chocolate has a set of numbers of (0, 0.75, 0.95) while Strawberry has a set of numbers of (0.7, 0.5, 0.1). Based on these numbers, cosine (Me, Chocolate) is much closer to 1 than cosine (Me, Strawberry), so Chocolate is the recommendation for me.
Recommendation Power
These techniques offer incredible power. In particular, recommendation systems now have the ability to compare any number of different things and do so quickly. We are now only limited by our ability to generate these numbers to represent “things”. And that is limited by our own creativity and thought process, not by computational power or algorithms. Personalization can be, and is, everywhere.
Recommendation Downsides
But these systems suffer from limitations. A common one that people encounter can be termed “fixation.” Once a recommendation system has a representation of you as numbers, you may be stuck in a loop where you are presented only with choices that are very similar to that set of numbers. You watched one video of a “Modern Family” clip, and suddenly you are overwhelmed with those clips. Why? Because that one engagement (watching the video) created a set of numbers that are then close to other Modern Family items. So now you only see that one type of thing - whether it’s a Modern Family video, or a Phil Dunphy doll.
Even in less extreme examples, a recommendation system is, by its very definition, geared to present to you suggestions based on what it knows about you; it recommends what you already like. These systems run the risk of boxing us into a “Walled Garden”: A location where we are restricted, whether we see it or not, by our existing preferences. We can observe this in so many social media sites, where content is recommended to us, reinforcing our existing likes and dislikes, and keeping us from growing and learning.
Randomness Powers
Remember that time when you were listening to the radio, not paying attention but all of a sudden a song came on that you loved (That’s how I first discovered Noah Kahan, for example)? Sometimes, the thing we will like is not something we currently know of. Our set of numbers does not account for the things that we don’t know about but might enjoy. Even if cosine (Me, Noah Kahan) had some reasonable value, it most certainly would have been smaller than cosine (Me, Bruce Springsteen). A recommendation system that prioritized similarity would be highly unlikely to present me with such a new item, something that can drastically change my listening, shopping, or reading habits.
What can lead to such a choice? Randomness. Randomness is unpredictable. Randomness is unexpected. Randomness leads to serendipity - the discovery of something new and enjoyable, purely by chance. Sure, it also leads to the garbage song that makes you reach for the “Skip” button. But it is also the technique that opens up a new avenue that you never knew about. Randomness opens a new door for you to expand your horizons.
Does this mean that recommendation systems have limited use? Of course not. Now that I’ve encountered Noah Kahan, I do greatly enjoy recommendations of similar artists. I’ve found a new genre that I otherwise would have missed. The most powerful recommendation systems can be the ones that mix the two.
Implementation Strategies
So how do we take advantage of the power of randomness? With the AI capabilities available to us within our existing systems, the answer may not be easy or obvious. What becomes most important is to understand how these AI capabilities are working and then make our own judicious decisions about when to override them and introduce new topics. Be creative, think differently.
For example, could you create random segments in your audience and then pick a different product to send to each segment? If you find a way to present your audience with something new and different, you open up avenues to learn more. When someone engages with unexpected content, you’ve learned something new and different about them. And you’ve quite possibly surprised and delighted them.
Conclusion
Incorporating randomness into recommendation systems is crucial for creating new opportunities to learn about people. By introducing an element of surprise, systems can reveal interests and preferences that might otherwise remain hidden. This balance between personalization and discovery ensures users are not limited by past behavior alone but can continue to explore, grow, and engage with diverse content.
Make sure you offer your audience that opportunity for Serendipity, through the appropriate use of Randomness.
 Photo by engin akyurt on Unsplash
Photo by engin akyurt on Unsplash
About the author
 Paul Christmann, Chief Innovation Officer, rasa.io
Paul Christmann, Chief Innovation Officer, rasa.io
5 years ago, Paul Christmann started his journey into the world of email. With over 20 years experience building SaaS products, Paul led the effort to create rasa’s AI-powered newsletter platform. As rasa has grown, Paul has championed efforts to measure how increasing the personalization of each individual email can lead to significant improvements in overall newsletter performance. As Chief Innovation Officer, Paul is now charged with furthering this effort - and exploring how other emerging technologies can build better newsletters.
Paul’s initial interest in software development, and algorithms in particular, started nearly 30 years ago, delivering solutions for aircraft scheduling for one of the largest US Airlines. He has since brought that passion for building software solutions to many different platforms and industries. Based in New Orleans, he is also an AVID fan of all things Notre Dame. Geaux Irish!